Descomplicando o SOLID
Descomplicando o SOLID
Para que eu deveria usar SOLID? É um conceito ultrapassado que cria uma resistência na velocidade de escrever código e vai contra a melhor metodologia que existe... A GoHorse.
Se você tem indícios desses pensamentos, sinto lhe informar, mas o seu software é uma bombar relógio prestes a explodir.
O SOLID é um grupo de conceitos muito conhecido quando se trata de desenvolvimento de Software... Para muitos ele acaba sendo algo complicado e difícil de entender, mas não é.
E hoje eu vou te provar que com um pouco de abstração é possível que até mesmo uma criança entenda o SOLID e perceba a importância da sua aplicação para gerir e manter aplicações a longo prazo...
E sim, talvez para o seu projeto de final de semana que não requer mais de um total de 5 arquivos e poucas linhas de código, seguir um GoHorse seja a melhor opção, mas tendo a consciência de que se ele crescer, sequer um pouquinho, você vai precisar reescrever 90% do código.
S: Single responsibility principle
Em termos técnicos, o princípio da responsabilidade única diz que cada entidade de um ecossistema deve ter uma única responsabilidade, mas a promessa era facilitar, né!?
Um bom exemplo, que remete ideias modernas, é a do pato...
O pato sabe nadar, sabe correr, sabe voar, mas ele não executa nenhum deles com excelência. Abstrações genéricas são, sim, importantes, mas elas podem se tornar um problema muito rápido se você não tem o habito de se perguntar: "De quem é esse código?"
Vamos a um exemplo prático:

O objetivo do código acima é simples... Ele armazena uma série de dados e tem métodos para manipular cada um deles e se você não viu problema algum, provavelmente os seus códigos estão acoplados de uma forma que dificulta a manutenção.
Não é muito difícil uma aplicação crescer a ponto de ter uma centena de pequenos estados diferentes, tornando inviável ter todos os estados contidos em apenas uma classe.
Vamos resolver parcialmente o nosso problema e adicionar alguns métodos:
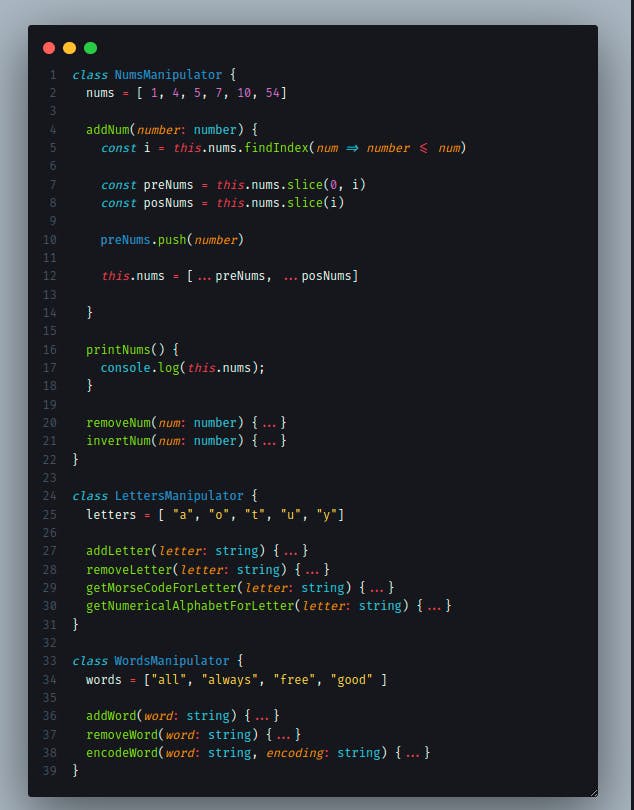
Agora temos 3 classes, cada uma contem uma série de métodos para manipular a sua própria estrutura de dados, mas isso é o suficiente?
Se olharmos diretamente para as linhas 29 e 30 vemos métodos para pegarmos valores que dizem respeito a coisas que estão presentes na estrutura de dados, porem isso diz mais respeito ao dado em si, de que a composição deles juntos...
Talvez os métodos de adição e remoção de dados realmente pertençam à classe de manipulação, mas os outros não, e para resolver isso a gente precisa granular ainda mais a nossa estrutura. Antes que me perguntem o porquê... Ainda estamos com estruturas que são um array com os valores simples e fáceis de manipular, mas se ficar um pouco mais complexo, pode custar caro iterar pelo array todas às vezes apenas para pegar um número de alfabeto numérico no caso da nossa função da linha 30.
Então vamos para a resolução do primeiro princípio do SOLID.


Bom, agora temos 2 classes. Cada uma com a sua função específica e escopo bem definidos. A classe Letter, quando instanciada, já cria seus "encodes" equivalentes, ausentando a necessidade de métodos por enquanto.
Note que há maior facilidade na leitura, menos código e uma maior facilidade de encontrar algo específico. São ordens de grandeza mais fácil dar manutenção no código atual, quando comparamos com a primeira versão...
O: Open-close principle
Principio do aberto-fechado? Mas o que diabos é isso?
Bom, esse principio diz que uma classe/entidade do seu software deve estar fechada para alterações, mas aberta para extensões, e aqui as coisas começam a ficar mais complicadas...
Olhando para o nosso programa de exemplo se torna visível a existências de algumas "Entidades". Letter, por exemplo, pode ser uma entidade, assim como Word, mas no final são todas derivadas de um único conceito: "Entidade".
E aqui é valido lembrar que existem vários debates de como se identifica uma entidade, ou até mesmo como se implementa isso.
Eu gosto de pensar que toda entidade tem um padrão único de identificação. Ou seja, ainda que a classe que cria a instância seja a mesma, os dados dentro dela são únicos... Únicos, não porque são totalmente diferentes, mas porque foram criados em momentos e contextos diferentes.
Um exemplo disso seria a classe Word, que quando instanciada cria várias Letters para representá-la. Supondo que eu instancie uma palavra "abacaxi", mesmo tendo 3 letras 'a', cada uma séria uma entidade diferente.
Eu poderia simplesmente adicionar um campo id em cada classe e pronto, mas perderia o exemplo do nosso segundo princípio e perderia a oportunidade de implementar mais uma vez o princípio da responsabilidade única...
Vejam por conta própria:

Primeiro eu criei essa classe de entidade... Ela é abstrata para não permitir uma instância direta com o new e tem suas propriedades privadas, pois elas estão fechadas para alteração... A nossa entidade também recebe uma tipagem genérica para definir que tipo de conteúdo existente dentro dela... Mais uma vez: essa é a minha forma de implementar, soluções diferentes podem e vão existir.


Depois bastou estender a entidade padrão, passando a tipagem do que vai existir dentro da minha classe e adicionar alguns métodos para conseguir instanciar ela. São métodos estáticos, pois o construtor é protegido e só pode ser instanciado por dentro da própria classe. Em outras palavras, eu só posso usar new dentro da própria classe.
O id é sempre opcional, pois eu posso instanciar uma referência para algo que já existe e não necessariamente criar um id do zero... Isso acontece na classe Entity onde tudo que diz respeito as entidades em si é criado e posto no seu devido lugar... Ou seja, minha classe Entity está aberta a extensão, mas nada altera ela diretamente.
Essa a base do segundo princípio.
L: Liskov substitution principle
O princípio da substituição de Liskov diz que uma classe pai deve ter a possibilidade de ser substituída por uma classe filho, sem que isso cause erro na aplicação.
Isso já foi implementado de uma forma rudimentar anteriormente, uma vez que qualquer Entidade pode substituir a classe Entity sem gerar erros, mas isso não é um bom exemplo, não é mesmo!? Afinal de contas, onde eu iria querer substituir a classe Entity?
Para que eu consiga te explicar esse principio, primeiro precisamos fazer alguns ajustar no nosso código para que ele respeite ainda mias os princípios anteriores. Como?
Bom...

O nosso código carrega esses dois objetos para mapear tanto o alfabeto numérico, quanto o código morse para todas as 26 letras do alfabeto. Esses dados são usados no momento em que uma instância da classe Letter é criada, como mostrei anteriormente e isso é um problema!
Primeiro que para cada tipo de encode diferente que eu queira adicionar, eu precisarei alterar a classe Letter, ferindo o Open-close principle, uma vez que o encode não tem a ver necessariamente com a classe Letter em si.
Segundo, que se eu tiver 10 encodes diferentes, cada Letter vai estar desperdiçando a memória de 9 deles, uma vez que o objetivo é fazer o encode para apenas um dos tipos de criptografia e após abrir para uma nova mensagem.
Então vamos resolver isso!

Primeiro eu criei uma classe base chamada Criptography, que guarda um valor padrão, em seguida duas outras classes, uma para o código morse e outra para o alfabeto numérico.

Depois disso, bastou remover as propriedades referentes a cada tipo de criptografia e adicionar uma para a letra já criptografada independente do tipo de criptografia. Eu recebo a classe que fará o encode via injeção de dependência e pego a letra criptografada equivalente a colocando dentro de sua propriedade.

Já na classe onde as letras são instanciadas, eu posso e vou usar qualquer uma das classes que estendem a Cryptography e isso não vai me gerar erros, uma vez que o método será sempre o mesmo para todos eles.
Agora eu tenho certeza que você entende onde e porque você vai querer substituir uma classe... Mesmo se eu tiver 100 criptografias diferentes, em momento algum eu preciso alterar a minha classe Letter, mas isso ainda não é uma verdade para a classe Word. Então vamos resolver isso com os princípios que faltam!
I: Interface segregation principle
O princípio de segregação de interface diz que não devemos forçar uma classe a implementar métodos que ela não precisa. Para exemplificar esse principio irei criar outra classe de criptografia que se chama Cifra de César.

O primeiro passo foi transformar a nossa classe Cryptography, a qual não fazia nada com o texto, em uma interface... Adicionei alguns métodos e fiz com que as classes que estendiam ela, agora a implementasse e é exatamente ai que mora o problema...

A minha interface define um tipo específico de dado para a propriedade cryptography, mas aqui eu preciso de um tipo diferente... Eu também queria que algumas classes tivessem carregamento dinâmico, lendo arquivos dentro do meu programa, mas se eu adicionar um método na interface, todas as outras precisaram implementar e isso fere o nosso princípio.
Vamos resolver isso...

A primeira coisa foi remover a tipagem da propriedade dos dodos dentro da interface Cryptography... Contanto que ela tenhas os métodos especificados e retorne os valores corretos, pouco importa a implementação dentro dela, ou como a classe que a implementa consegue esses dados.
Isso nos ajuda a ter uma visão mais focada e uma facilidade em isolar um possível problema.
A segunda coisa foi criar outra interface para uma criptografia com carregamento dinâmico que não interferem nas que não possuem esse carregamento.
Tendo isso em vista, podemos ir para o último princípio e na minha opinião, o mais genial deles.
D: Dependencie inversion principle
O princípio da inversão de dependência, frequentemente confundido com a injeção de dependência, diz que uma classe de nível superior não deve depender de uma classe de nível inferior e sim de uma abstração.
Em outras palavras, um código que fica mais próximo do usuário jamais deve depender de um código que está próximo ao core da aplicação diretamente, mas sim de uma abstração entre eles.
A gente fez isso indiretamente quando transformamos a classe de criptografia em uma interface, de forma que se precisarmos passar uma instância de classe, deveremos, obrigatoriamente, usar a interface, ao invés da declaração da classe.
Isso colide outra vez com o princípio de substituição de Liskov.
Dessa forma a instância da classe é declarada antes do seu uso, pois ela será passada como parâmetro...
Conclusão
Olhando a evolução do nosso código, podemos ver que as camadas estão com uma definição maior e com muito menos acoplamento, ajudando na expansão e manutenção do código.
Vale mencionar que esse código é muito mais fácil de ser testado, via Testes automatizados e caso você tenha interesse nesse assunto, basta ficar de olho por aqui.
Se quiser ver a conclusão desse projeto, com explicação dos conceitos em vídeo, basta acessar o canal no YouTube. Clique aqui para ver o vídeo
Espero ter esclarecido esse conceito super importante para como escrevemos códigos mais mentíveis...
Até a próxima!